Apple's New Multimodal LLM Model - A Game Changer for Computer Vision?
Imagine a world where computers can see, understand, and interact with the world just like humans do.
Apple's new multimodal LLM model is making this a reality, revolutionizing the field of computer vision.
Apple has collaborated with the Swiss Federal Institute of Technology Lausanne to create the Apple LLM Model 4M AI Model on Hugging Face.
Seven months after the model's initial open-source launch, this release marks a huge change in democratizing access to advanced AI technology.
With this public demo, a wider range of users can now explore and evaluate the remarkable capabilities of the 4M model firsthand.
But what is the 4M Model? What are its capabilities? Why is it created?
Let's find out -
What is Apple’s New Multimodal LLM Model?
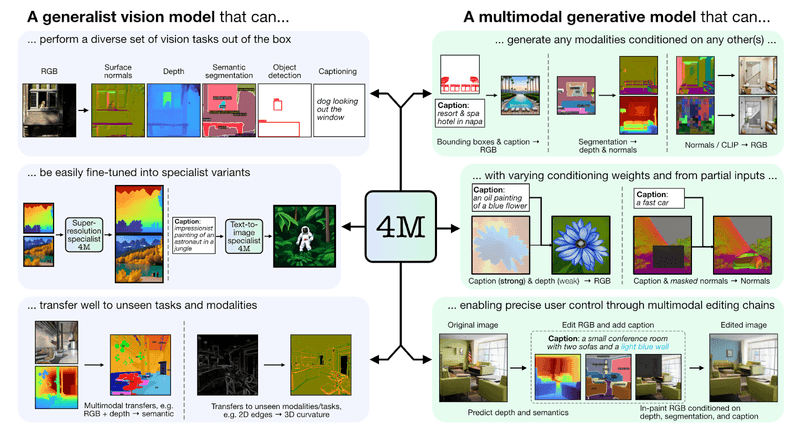
Apple recently released a public demo of their new AI model 4M, allowing anyone to play around with this exciting technology.
This AI model called 4M can handle different types of information, not just text. You can describe a scene with just a few words, and then you can use the 4M model to create an image for you. 4M can also find objects in pictures and even change 3D scenes using just your instructions.
Key Capabilities of the 4M Model
Out-of-the-box Versatility: 4M can handle various image-related jobs right from the start, like identifying objects in a picture.
Always learning: The Apple 4M Model is not limited to a set of tasks. It can be easily trained for even more specialized skills.
Open to all: Apple released 4M publicly so you can use it right now. Just visit the Hugging Face Platform and access the model.
Image Creation with a Twist: Also, 4M isn't just for viewing images; it can create images too. You can just describe a scene with words and have 4M generate a picture based on your description.
These 4M capabilities translate to exciting applications:
Smarter Photo Editing Tools: You can edit photos by saying things like "make the sky brighter" or "remove that red car."
Automated Image Description: The Apple 4M model could automatically generate captions for images by just providing it with an image, making information retrieval easy.
Why is Apple's New multimodal LLM model a big Breakthrough?

This release is a big deal because Apple is usually quite secretive about its research. By making their 4M model public, they're not only showing off their cool AI but also inviting others to play with it and develop even more amazing things.
Here's the gist of how it works: The 4M model takes all sorts of information, like text, pictures, and even 3D shapes, and turns it into a special code. Then, it uses this code to understand what you want and create something new, like an image based on your description.
Also, the 4M model solves the traditional computer vision restrictions. Traditionally, AI models are good at one specific task. 4M is different - it's like a super-powered AI that can do many things. Let's look at the challenges a little closer.
The Challenges of Traditional Computer Vision

Imagine a toolbox with only a hammer. Great for nails, but not much else. That's kind of how traditional computer vision works. These models are trained for one specific task, like recognizing faces, and struggle with anything else.
Lack of Versatility: These models are typically trained for a specific task, like object detection or facial recognition. They struggle to adapt to new situations or perform different tasks.
Limited Application: Because they rely on very specific data, these models can't handle variations in lighting, object position, or background clutter
Here's the catch: The world is full of information beyond just images. Text descriptions, for instance, can be incredibly helpful. That's where multimodal learning comes in. It allows machines to understand information from different sources, like text and images, together.
Think about this: You see a blurry picture of a cat. The text next to it says "Wearing a hat." A multimodal system could combine the image and text to understand it's a cat, and even what kind of hat it's wearing!
This is exactly what Apple's new 4M model is doing. It's a versatile AI that can handle both images and text, create images from descriptions, identify objects even in bad pictures, and manipulate 3D scenes using natural language.
Conclusion
In summary, Apple's new 4M model is a multimodal LLM, meaning it can understand and process both text and images. This is a significant advancement over traditional computer vision models that are limited to one task. 4M can create images from descriptions, identify objects in bad pictures, and even manipulate 3D scenes. Apple 4M is public, and anyone can use it by going to the Hugging Face Platform.
Also, since May 1st, Apple’s stock has surged by an impressive 24%, boosting its market value by over $600 billion. Making Apple one of the leading performers in the tech industry, after Nvidia in terms of market value growth.
The market’s enthusiasm indicates that investors now regard Apple as a significant player in the AI space, a view strengthened by its recent partnership with OpenAI. So we might even see many more powerful LLMs or new technologies coming from Apple in the future.
However, the release of 4M raises crucial questions about data handling and AI ethics. Apple, known for its strong stance on user privacy, may face challenges due to the data demands of advanced AI models. We need to see what type of technologies Apple brings to protect users' data and privacy.
Faqs
1. What exactly can the Apple 4M model do?
The Apple 4M model can understand and process both text and images. It can create images from descriptions, identify objects in images, and manipulate 3D scenes using natural language instructions.
2. Is the Apple 4M model creative?
Yeah, the 4M model can be creative by generating new images based on and also manipulating 3D scenes according to your descriptions.
3. Can we use the Apple 4M model on the iPhone?
Yeah, you can, but you need to go to the Hugging Face platform, and there you can use the Apple 4M model. You cannot use it directly on your iPhone as it is not a built-in feature.
