RAG vs LLM Fine-Tuning: Which AI Approach Saves You Time & Money? (2026) | Comprehensive Guide
Recent experimental study found that RAG systems with specialized fine-tuning for real-world imperfect retrieval can improve factual accuracy by 21.2% over the base LLM model.
But does that make LLM models less effective? Let’s try to understand that in this guide on RAG vs Fine-tuning. We'll explore everything you need to know about these two powerful approaches to improving AI model performance that are changing how businesses and individuals interact with artificial intelligence.
Here is what we are going to cover:
- What is RAG and how does it actually work
- What is LLM fine-tuning and how is it different
- How to get started with LLM fine-tuning
- How to get started with RAG
- When should you pick RAG over fine-tuning
- When does fine-tuning actually make sense
- Specific use cases for both RAG and fine-tuning approaches
- How tools like Elephas can help you use RAG for personalized knowledge bases
By the end of this article, you'll understand the key differences between RAG and fine-tuning, know which approach suits your specific needs, and discover how tools like Elephas make RAG accessible to everyone without technical expertise or expensive training processes.
Let's get into it.
Quick overview: Difference between RAG and fine-tuning
Comparison Factor | RAG (Retrieval-Augmented Generation) | LLM Fine-tuning |
Setup Time | Immediate - Start using right away | Hours to weeks - Requires extensive training |
Cost | Low cost - Monthly subscription (e.g., Elephas starts at 14.99/month) | High cost - Thousands in computing resources |
Technical Skills Required | None - User-friendly tools available | High - ML expertise, Python, neural networks |
Updates | Instant - Add documents in minutes | Complex - Requires complete retraining |
Accuracy Improvement | High with no hallucinations | High consistency but may have some hallucinations |
Data Privacy | Excellent - Can run offline (Elephas) | Moderate - Data used for training |
Response Speed | Slightly slower - Needs database search | Fast - Built-in knowledge |
Data Requirements | Any documents - PDFs, web pages, youtube videos | Large datasets - Thousands of samples |
Maintenance | Minimal - Just add new documents | High - Ongoing model management |
Knowledge Source | External documents or youtube videos - can be always updated | Training data - Can become outdated |
Scalability | Easy scaling - Add more documents | Difficult scaling - Requires retraining |
Learning Curve | Beginner-friendly - No technical knowledge | Expert-level - Requires ML background |
Enterprise Readiness | Ready - Tools like Elephas available | Complex - Needs dedicated teams |
Deployment | Instant deployment with existing models | Requires model hosting infrastructure |
Error Handling | Easy to fix - Update source documents | Difficult - May need complete retraining |
What is RAG?
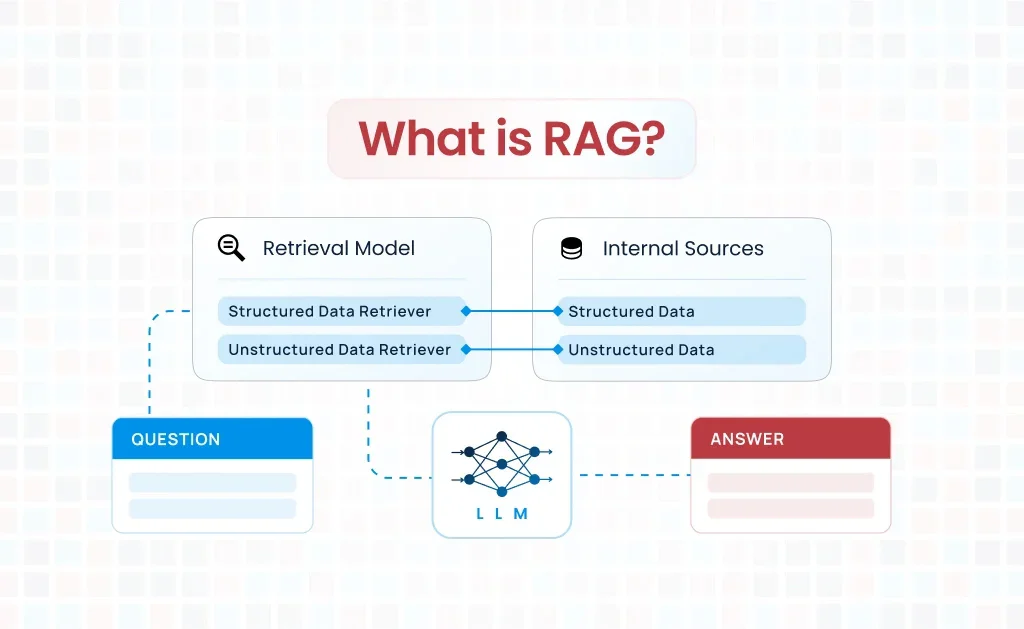
RAG stands for Retrieval-Augmented Generation. This technology combines two important processes to help AI systems provide better and more accurate answers.
The first part is retrieval. This means the AI system searches through a large collection of documents or data to find relevant information(You can create a large collection of documents, like a knowledge base; the system will retrieve information from there). It can quickly look through thousands of files to find the most useful pieces of information related to your question.
The second part is generation. After finding the relevant information, the AI uses this data to create a complete and helpful response. The AI takes the retrieved information and puts it together in a way that directly answers what you asked.
How does RAG actually work?
RAG works through a simple step-by-step process:
- Information Storage: First, documents and data get stored in a special database where they can be easily searched
- Query Processing: When you ask a question, the system breaks down your question to understand what information you need
- Smart Search: The system searches through all stored information to find the most relevant pieces that relate to your question
- Content Selection: It picks the best and most accurate information from what it found during the search
- Response Creation: Finally, the AI combines this selected information with its own knowledge to write a clear and complete answer
This process happens very quickly, usually in just a few seconds. The main benefit is that RAG helps AI systems give more accurate answers because they can access up-to-date information from reliable sources rather than relying only on their training data.
What is LLM fine-tuning and how is it different?

LLM fine-tuning is a process where an existing AI language model gets additional training on specific data to make it better at particular tasks. Instead of training a completely new AI model from scratch, fine-tuning takes a model that already knows language basics and teaches it specialized skills.
During fine-tuning, the AI model learns from new training data that focuses on specific topics or tasks. This process adjusts the model's internal settings to make it perform better in targeted areas. The model keeps its general language abilities but becomes much more skilled at handling specific types of work.
Key differences from RAG
Fine-tuning works very differently from RAG in several important ways:
- Learning Method: Fine-tuning actually changes how the AI model thinks and responds by updating its internal knowledge, while RAG keeps the original model unchanged and just adds external information
- Data Integration: Fine-tuning permanently builds new knowledge into the model during training, but RAG pulls information from outside sources each time you ask a question
- Update Process: Making changes to a fine-tuned model requires retraining the entire system, while RAG systems can update their information by simply adding new documents to their database
- Response Speed: Fine-tuned models can answer questions faster because all knowledge is built-in, whereas RAG systems need extra time to search through external databases
- Resource Requirements: Fine-tuning needs significant computing power and time for training, while RAG systems mainly need storage space for their document collections
The main advantage of fine-tuning is that it creates models with deep, specialized knowledge that responds quickly and consistently.
How to get started with LLM fine tuning

Getting started with LLM fine-tuning requires careful planning and the right resources. This process involves taking an existing AI model and training it further with your own data to make it work better for your specific needs.
The first step is choosing a base model to work with. Many companies offer models that you can fine-tune, such as those from OpenAI, Anthropic, or open-source options. You need to pick a model that already performs well on general tasks and has the capability to be customized for your specific use case.
Essential requirements for fine-tuning
Before starting the fine-tuning process, you need several important things in place:
- Large Dataset: You need thousands or even tens of thousands of training samples that show the AI how to handle your specific tasks correctly
- Technical Skills: Understanding machine learning concepts, programming languages like Python, and how neural networks work is necessary
- Computing Resources: Fine-tuning requires powerful computers with special graphics cards or cloud computing services that can handle intensive processing
- Time Investment: The training process can take hours, days, or even weeks depending on your data size and model complexity
- Quality Control: You need systems to test and validate that your fine-tuned model works correctly and safely
- Data Preparation: Your training data must be cleaned, formatted properly, and labeled correctly before the fine-tuning process begins
The technical knowledge required includes understanding how to prepare training data, set training parameters, monitor the learning process, and evaluate results. Most successful fine-tuning projects also need ongoing maintenance and updates as requirements change over time.
But users can also buy directly fine-tuned LLM models either as API keys, or they can even have local fine-tuned models (requires technical expertise to set up). However, these are usually expensive and also need technical knowledge and software to plug and play the API keys.
How to get started with RAG

Getting started with RAG is much simpler and more cost-effective than training your own AI model. Unlike fine-tuning, which requires extensive technical knowledge and expensive computing resources, RAG systems can be set up quickly and work with existing AI models without any complex training processes.
RAG offers several advantages over fine-tuned models. The setup process is straightforward, costs much less money, and you can start using it right away. You also get more accurate responses because the system pulls information directly from your own documents rather than relying on potentially outdated training data.
Using RAG tools like Elephas
Tools like Elephas make RAG technology accessible to everyone. Elephas is a Mac knowledge assistant that uses RAG technology to help you work with your own documents and information.
- Super Brain Feature: Elephas includes a feature called Super Brain where you can upload all your PDFs, documents, and other files to create your personal knowledge base
- Chat with your knowledge:: You can ask questions about your uploaded content, and the system only retrieves answers from your knowledge base, which eliminates wrong information
- Offline Capability: Elephas can also can run offline using local AI models, which means your data stays on your device for better privacy and security
- Easy Updates: Adding new information is simple - just drop links to YouTube videos, webpages, or instruction manuals into Super Brain and start chatting with the content immediately
- Multiple Formats: You can create diagrams, tables, and other visual content based on your uploaded information
- Always Current: Unlike fine-tuned models that become outdated, your RAG system stays current because you can continuously add new documents, webpages, youtube videos and even your zoom meeting notes and information as needed
The main benefit of using Elephas as your RAG system is that you can run it offline, or you can even use your own custom API key from OpenAI, Claude, Google, or any other AI providers to run Elephas. You also have a ton of other features like writing, automation, web search, and many more.
How to use Elephas as your personal RAG system?
Setting up Elephas is straightforward; download the Elephas Mac app. If you are just starting out, you can try Elephas for free and see how well it resonates with your workflow.


Once you install the app, you can create your super brain and start creating your custom knowledge base. You can add YouTube videos, webpages, snippets of information, and you can even connect Elephas with PKM tools like Notion, Obsidian, etc., and also connect with Zoom meetings and Apple Notes with just a click.
You can check the Elephas chat interface from the image below. You can summarize your knowledge base, create preparations, mind maps, etc., from the chat interface, and you can also customize the chat prompt according to your needs.


Along with the super brain feature, Elephas also has several other features such as the writing features like writing tone replication, rewrite modes, email replies, quick web search, etc.
But one of the most powerful features that Elephas has is workflow automation, where users can automate their repetitive tasks such as an entire workflow like searching the web for a subject, adding important sources to a custom super brain, and then summarizing it in the chat, and also even create presentation, all with a single click.
Users can even create custom workflows according to their needs or try out the default workflow agents library in Elephas.

When should you pick RAG over fine-tuning?

RAG works better in most situations where you need accurate, up-to-date information from your own documents. This approach makes sense when you want quick results without the complexity of training AI models.
Choose RAG when you have documents that change frequently or when you need to add new information regularly. RAG systems can instantly access updated content by simply adding new files to your knowledge base. This makes RAG perfect for businesses that deal with changing policies, updated manuals, or growing document collections.
RAG is the better choice when you need:
- Quick Setup: You can start using RAG systems immediately without weeks of training time
- Lower Costs: RAG requires much less money since you avoid expensive training processes and computing resources
- Easy Updates: Adding new information takes minutes instead of retraining entire models
- Accurate Citations: RAG systems can show you exactly where information comes from in your documents
- Privacy Control: Your sensitive data stays in your own system rather than being used to train external models if you use tools like Elephas.
- Multiple Data Types: RAG handles various file formats like PDFs, websites, videos, and documents without special preparation
Specific RAG use cases with Elephas:
- Student Learning: Using Elephas, students can create custom knowledge bases by uploading their class notes, lecture materials, and textbooks. Elephas helps them create study summaries, plan their study schedules, and get quick answers from their course materials, making learning much easier and more organized
- Legal Practice Management: Lawyers can use Elephas offline with local AI models to ensure their sensitive case files and legal documents never leave their devices. They can create secure knowledge bases from case law, client files, and legal research while maintaining complete privacy and confidentiality
- Healthcare Research Organization: Medical practitioners can quickly build separate knowledge bases in different Super Brains within Elephas for various research topics, medical studies, and treatment protocols. This helps them stay current with the latest medical developments and access relevant information instantly during patient consultations
Anyone can use Elephas and have productive weeks, cutting out several weeks of work doing repetitive tasks. To take a step further, Elephas also has features like workflow automation where users can create custom automated workflows for all of their repetitive tasks, like searching the web, creating presentations, etc.
When does fine-tuning actually make sense?

Fine-tuning makes sense in specific situations where you need the AI model to behave in very particular ways or handle specialized tasks that require deep understanding.
Choose fine-tuning when you need the AI to consistently follow specific writing styles, tone, or response patterns that match your brand or organization. Fine-tuning also works well for highly specialized technical domains where the AI needs to understand complex relationships and concepts that cannot be easily retrieved from documents.
Fine-tuning is worth the effort when you have:
- Consistent Style Requirements: You need all responses to follow exact formatting, tone, or writing standards
- Specialized Domain Knowledge: The AI must understand complex technical relationships that go beyond simple document retrieval
- High-Volume Repetitive Tasks: You process thousands of similar requests where consistent behavior matters more than accessing new information
- Limited External Dependencies: You want the AI to work without needing to search through external databases every time
- Long-term Stability: Your requirements will not change frequently, making the training investment worthwhile over time
Specific fine-tuning use cases:
- Enterprise-Wide Business Systems: Large corporations fine-tune models to create centralized AI systems that all employees can use for various tasks like writing reports, analyzing data, and handling customer communications. This ensures consistent quality and behavior across all departments while maintaining company standards
- Specialized Code Generation: Software companies create fine-tuned models that generate code following their specific coding standards, architecture patterns, and internal frameworks that would be difficult to explain through documents alone
- Financial Analysis Reports: Investment firms fine-tune models to analyze market data and write financial reports using their proprietary analysis methods and specific terminology that clients expect to see in professional investment communications
Conclusion
Both RAG and fine-tuning serve important roles in improving AI model performance, but RAG is the clear winner for most users and businesses. The simplicity, cost-effectiveness, and flexibility of RAG make it the practical choice for anyone looking to enhance their AI interactions with personalized knowledge.
RAG systems like Elephas offer the perfect balance of power and accessibility. You can start using RAG immediately without technical expertise, expensive training costs, or complex setup processes. The ability to continuously update your knowledge base with new documents, websites, and information keeps your AI assistant current and relevant.
Whether you are a student organizing study materials, a lawyer managing sensitive case files, or a healthcare professional staying updated with research, RAG provides accurate, sourced responses from your own trusted documents.
While fine-tuning has its place in specialized enterprise applications, RAG delivers superior value for most use cases. Choose RAG with tools like Elephas to change your productivity and access your knowledge instantly, safely, and efficiently.
