AI for Sensitive Data: A Complete Guide to Using AI Tools Without Exposing Sensitive Company Information
On February 17, 2026, a federal judge ruled that 31 Claude chat sessions belonging to a former CEO were neither attorney-client privileged nor work product. The chats are now part of the federal prosecution's case. Most of the work knowledge professionals get paid to do flows through tools like that one every week.
This guide covers what “sensitive data” really means in 2026, why default tools quietly fail it, and what a professional workflow looks like instead. It's for lawyers, doctors, therapists, advisors, HR leaders, journalists, and consultants. The trade-off is the same for all of them.
31
Claude chats admitted in Heppner ruling
49%
Workers using AI without employer approval
98,034
Sensitive-data exposures on free AI tiers
Aug 2
EU AI Act enforcement starts (2026)
Executive Summary
- Sensitive data isn't an industry — it's a data trait. Any information with a legal, contractual, ethical, or fiduciary duty inherits that duty into whichever AI tool touches it.
- OpenAI's Terms of Use and Anthropic's privacy policies both allow inputs to be used to train and improve services. Default consumer chatbots fail sensitive work by construction.
- The 2026 Heppner ruling, the EU AI Act enforcement clock, and the CISA director ChatGPT incident all converge to make this the breaking-point year.
- A 4-tier deployment decision tree (Consumer cloud / Enterprise+BAA / Redact-then-cloud / On-device) maps the safe path for each kind of work.
- A 6-point evaluation framework decides whether any AI tool is right for THIS data: training, retention, BAA/DPA, inference location, sub-processors, and zero-retention verification.
- If you'd rather skip the trade-offs entirely, try Elephas — a privacy friendly AI knowledge assistant with built-in local LLM models, so your sensitive data never leaves your Mac.
When Your Private AI Chat Becomes Court Evidence
On February 17, 2026, Judge Jed S. Rakoff of the Southern District of New York ruled that 31 Claude chat sessions belonging to a former CEO were neither attorney-client privileged nor work product, and were fully admissible against him. The defendant, Charles Heppner, used a top-tier chatbot the way millions of professionals use it every week. According to this federal ruling on attorney-client privilege, the chats are now part of the federal prosecution's case.
Think about your last 24 hours. A contract reviewed at 8 PM. A patient note dictated between appointments. A source quote tightened before filing. An offer letter polished on the train. Most of that work probably went through a consumer chatbot tab. Heppner's did too.
If those 31 chats were not private for a man under federal indictment, why would yours be private for a malpractice complaint, a healthcare audit, or a wrongful-termination filing?
- The default consumer tier of every major chatbot allows training on inputs.
- AI conversation history is now discoverable evidence in U.S. courts, per Heppner.
- The EU AI Act's most-cited rules begin enforcement on 2 August 2026.
What Sensitive Data Means When You Use AI in 2026
Sensitive information, in the context of artificial intelligence, is any data point that carries a legal, contractual, ethical, or fiduciary duty: client files, patient records, financial accounts, deal documents. Personal data under data protection law is the headline category. Health-related records, financial data, and confidential information from a regulated company all sit alongside it.
A useful primer on private AI tools for professionals frames it the same way. Such work is not a job title. It is a data trait. The minute a piece of information has a duty attached to it, the model you use inherits the duty.
- Lawyers and patent attorneys: attorney-client privilege under ABA Rule 1.6 and trade-secret status.
- Doctors and therapists: protected health information (PHI) under HIPAA Privacy Rule 45 CFR Part 164.
- Financial advisors and CPAs: non-public personal information under SEC Reg S-P and FINRA's 2026 oversight focus.
- HR directors: employee PII and Article 9 special categories under GDPR.
- Journalists and consultants: source protection, NDAs, and material non-public information (MNPI).
Information sensitivity is the through-line. Each item travels the same path the moment it lands as input into a prompt window. That is the whole risk in one sentence.
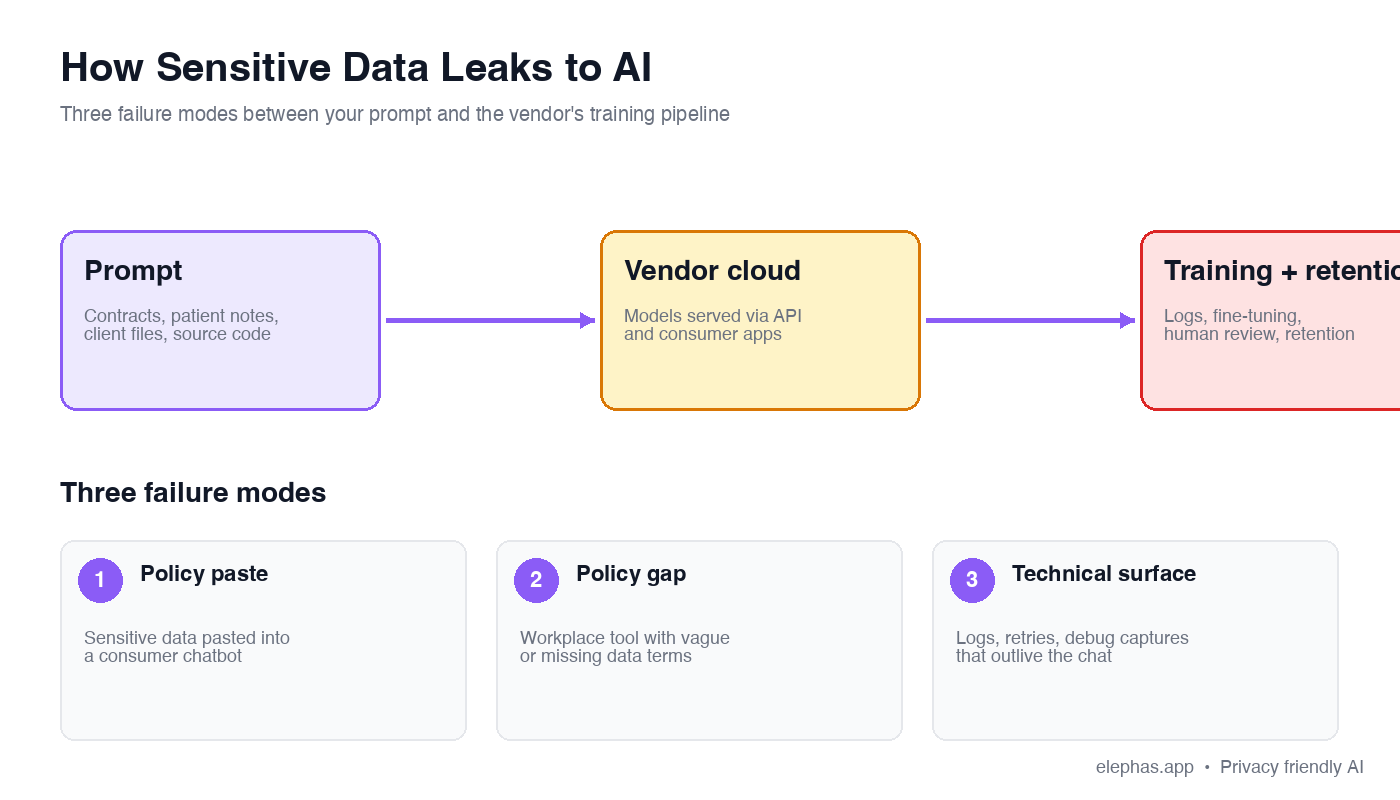
How AI Tools Expose Sensitive Customer Data
Three failure modes break the safe path most professionals assume they are on. Each is documented in vendor terms or independent telemetry.
- The policy paste: OpenAI's Terms of Use state plainly: “We may use Content to provide, maintain, develop, and improve our Services.” Anthropic's privacy policies read the same way.
- The policy gap inside the org: Per CIO.com's April 2026 reporting, 49% of workers admit to running prompts without employer approval, and 38% have shared sensitive work content with consumer assistants.
- The technical surface itself: In April 2026, Check Point Research disclosed a class of ChatGPT vulnerabilities that silently exfiltrated user prompts, uploaded PDFs, and attached medical records to attacker-controlled servers. The user saw nothing in the UI.
Harmonic Security telemetry covered by The Hacker News found that 16.9% of all enterprise sensitive-data exposures (98,034 separate instances) happen on personal free-tier accounts that are invisible to corporate IT. A separate analysis on whether the popular chatbot preserves attorney-client privilege reaches the same conclusion: it does not.
Under the hood, the same software stack that powers cloud computing concentrates the risk. Vendor pipelines pull rows from a database via SQL, run ETL (extract, transform, load) jobs to build a clean data set, and feed federated learning experiments designed to mine new data. One stray paste flows through that stack and into training data. IBM has published similar findings on machine learning leakage paths.
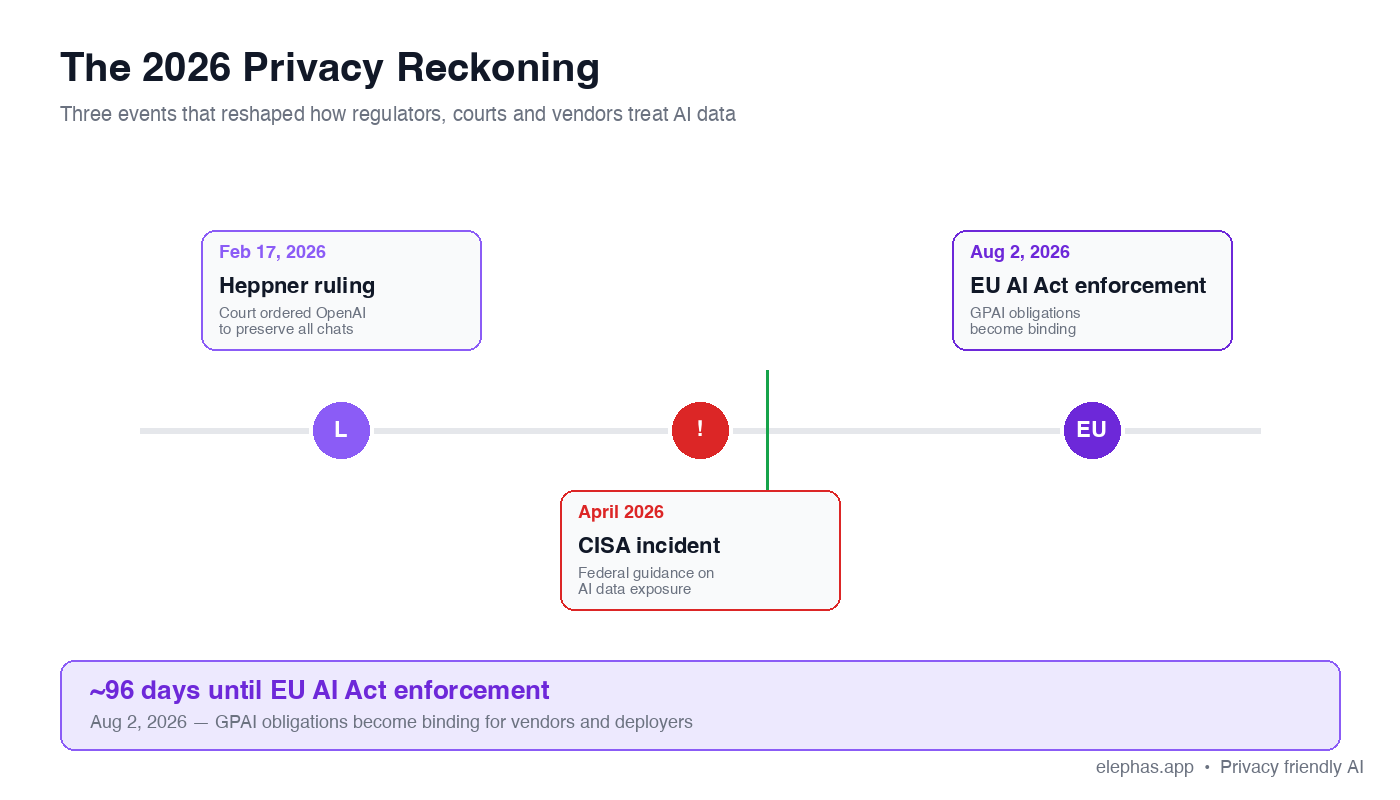
Why 2026 Is the Data Privacy Breaking Point for Generative AI Use

For two years, the question of whether your conversation with a vendor was confidential was hypothetical. In 2026 it stopped being hypothetical. Three forces made the change concrete.
- Anchor 1 (Feb 17, 2026) — the Heppner ruling. The court held that machine-generated documents are not protected by attorney-client privilege or work product. Thirty-one Claude chats went into the prosecution's binder. Lawfare's analysis is the canonical reference.
- Anchor 2 (Aug 2, 2026) — regulatory enforcement. The European Parliamentary Research Service confirms that on 2 August 2026 the majority of the new rules come into force. FINRA's 2026 Regulatory Oversight Report added a generative AI applications section, and Norton Rose Fulbright described consumer training behavior as a direct violation of healthcare confidentiality protections. A practical guide to healthcare AI compliance covers the BAA path.
- Anchor 3 (April 2026) — the CISA incident. Reporting in April 2026 alleged that the acting director of the Cybersecurity and Infrastructure Security Agency used a consumer chatbot for sensitive material. Default consumer chatbots and the large language models behind them retain prompts by construction.
Add the security risks tied to plug-ins, browser agents, and silent prompt injection, and the privacy risks tied to multi-tenant inference, and you get the picture: AI risk has moved from a thought experiment to an active threat model. Reputational damage from a single leak can outlast the headline by years, and the regulatory compliance cost compounds as AI technology matures.
Using AI Tools Without Sharing Sensitive Data: A Workflow for Real Work
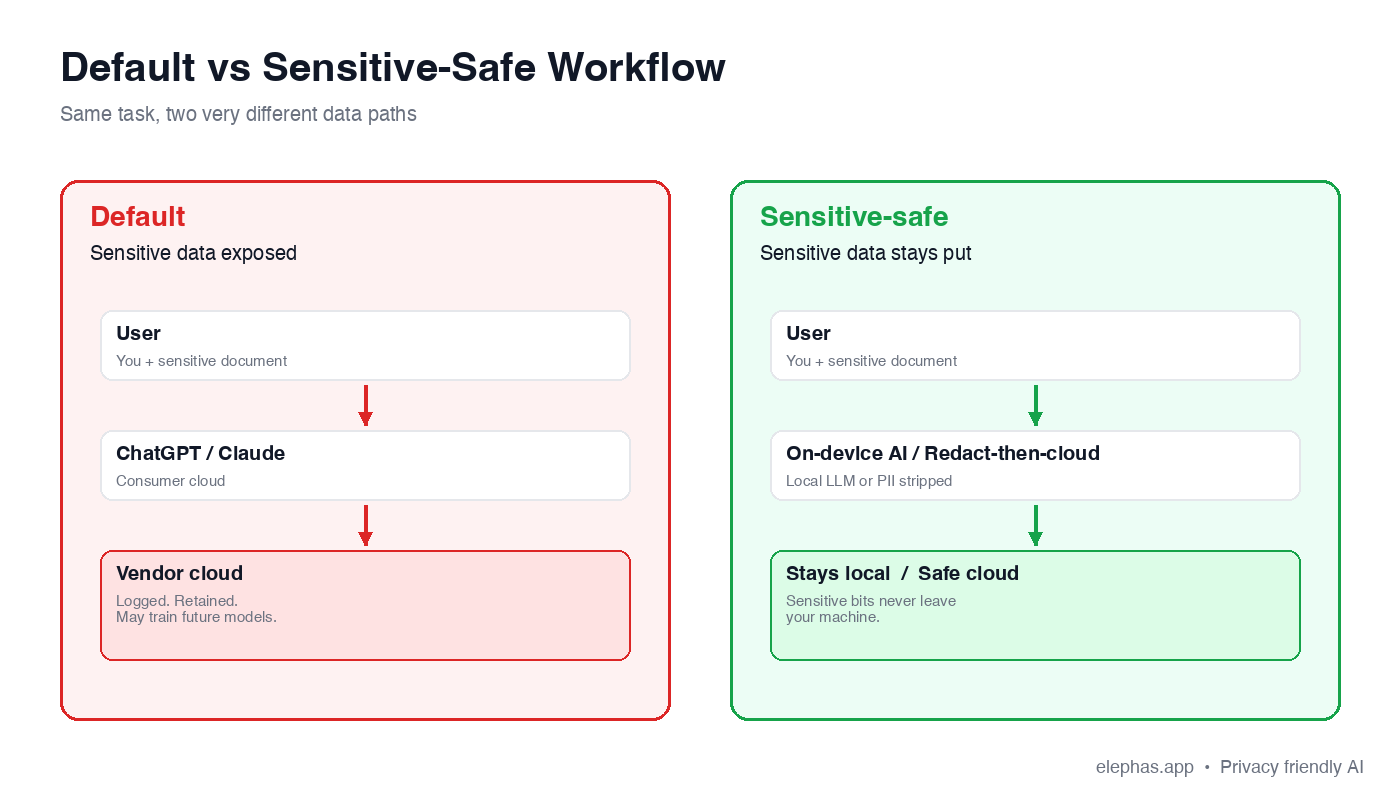
A safer approach is not a heavier process. It is a slightly different sequence of steps that moves the sensitive part of the job onto the device, and only the desensitized part to the cloud. The 4-tier deployment decision tree maps where each kind of work belongs.
The 4-Tier Deployment Decision Tree
- Tier 1 — Consumer cloud AI (UNSAFE): Default ChatGPT, Claude, Gemini in the consumer tab. Inputs feed training, retention is open-ended, conversation history is discoverable in litigation.
- Tier 2 — Enterprise + BAA/DPA (CAUTION): Signed contract, verified zero-retention configuration, named sub-processors. Safer, but data still leaves the device.
- Tier 3 — Redact-then-cloud (VIABLE): PII gets stripped on the user's Mac, then a sanitized prompt goes up. Pseudonymization at the boundary.
- Tier 4 — On-device AI (SAFEST): Prompt and data never leave the Mac. Built-in local LLM models replace the trip to a cloud vendor entirely.
A deeper write-up on tools that keep client data private walks through the same playbook for legal teams. Pair the tier choice with a 6-point evaluation framework before any AI tool touches sensitive data.
- Confirm whether the tool trains on your inputs.
- Confirm the retention window in writing.
- Confirm the vendor will sign a BAA or DPA when required.
- Confirm where inference runs — on the device or in the cloud.
- Identify every sub-processor in the data path.
- Verify the zero-retention option, end to end, before relying on it.
Agentic AI with Built-In Data Discovery: The Elephas Approach
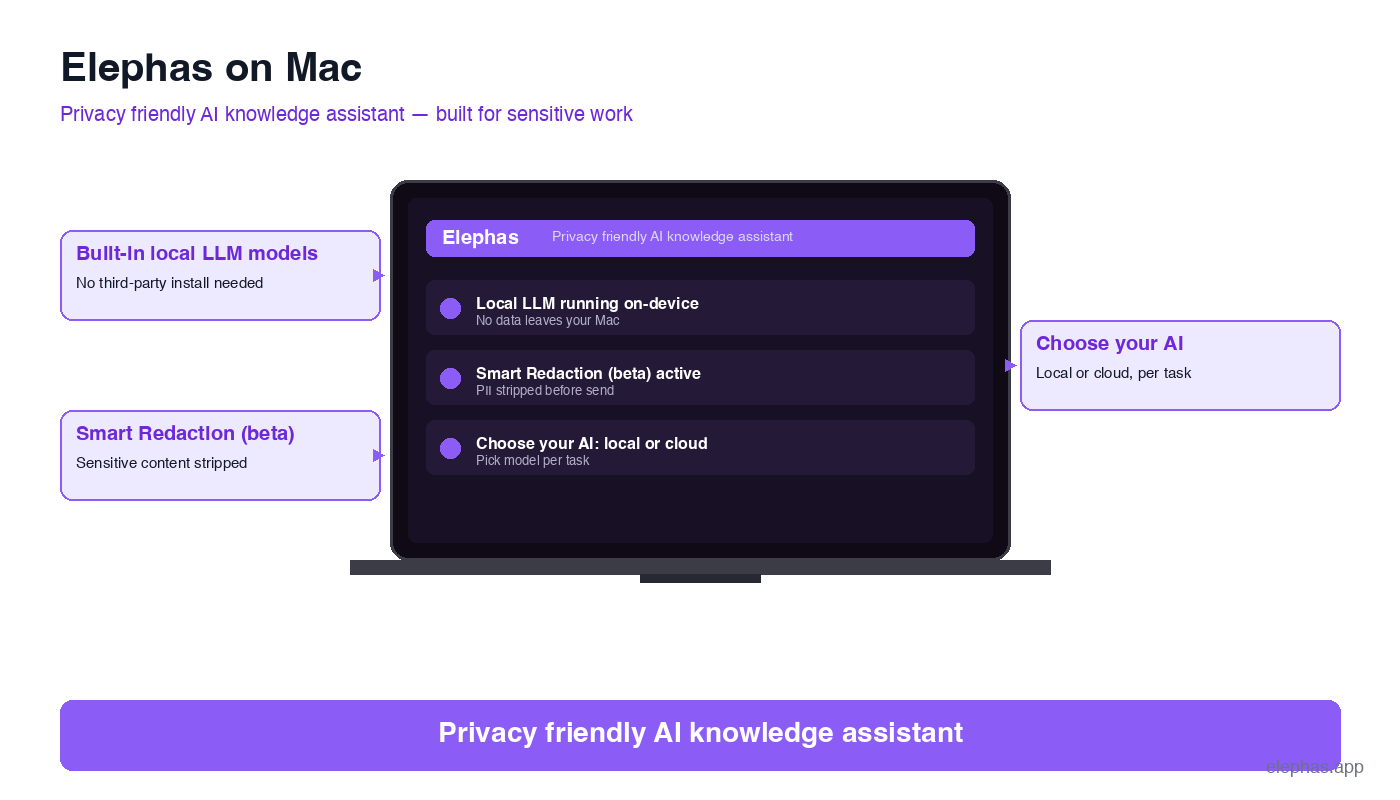
Most patterns above share three building blocks: a model that runs on the user's Mac, a redaction layer that fires before any cloud call, and the freedom to choose which cloud handles the few prompts that do leave. Elephas is a privacy friendly AI knowledge assistant for Mac, iPhone, and iPad built on exactly those three blocks. A short overview of Elephas for legal teams shows how it lands in practice.
- Built-in local LLM models on the device. Elephas provides built-in local LLM models on the Mac. Built-in means no third-party install (Ollama, llama.cpp, or similar) is required. Prompts stay on the device by default, not as a power-user mode.
- Smart Redaction (in beta) with built-in scanning. Behind the scenes, an agent scans the document, an autonomous step decides what to mask, and the cleaned prompt is what the cloud sees.
- Choose your model. Pair Elephas with Claude Opus 4.7, ChatGPT 5.4, Gemini, Microsoft Copilot, or fully offline LLMs. Elephas wraps the chosen frontier model with privacy; it does not replace it.
“Sensitive data is automatically detected and redacted before anything reaches a cloud AI model, your content is never used to train AI models, and nothing passes through a third-party reviewer's screen.”
Best Practices to Adopt Tomorrow Morning
If the August 2 enforcement deadline is fourteen weeks out and the Heppner ruling is already cited by the time you read this, the single thing worth doing is auditing the routine you already use. The ABA Opinion 512 compliance guide is a good companion read for lawyers, and the same checklist transfers to other professions.
Run the 3-point pocket framework on tomorrow's most sensitive task before you open any ai-powered tab. Pick a contract, session note, portfolio review, HR memo, or source thread. Anything failing the three checks moves to on-device or redact-then-cloud. Anything passing stays on the current tier with retention confirmed in writing.
- Treat data privacy regulations as the floor, not the ceiling. Build for the strictest jurisdiction your data touches.
- Treat data privacy and compliance as a single program. AI ethics belongs in the same review, alongside information privacy.
- Map the data privacy challenges specific to your team (BYOD, contractor access, model sprawl) and write a one-page plan for each.
- Use data anonymization at the boundary, supported by automation. The only fully safe paste is the anonymized one.
- Read vendor privacy policies once a quarter. Terms change quietly, and the benefits of AI evaporate the moment they do.
- If you'd rather skip the trade-offs entirely, try Elephas — a privacy friendly AI knowledge assistant with built-in local LLM models, so your sensitive data never leaves your Mac.

Frequently Asked Questions
Is it safe to enter sensitive data into ChatGPT or Gemini?
By default, no. OpenAI's Terms of Use and Anthropic's privacy policies allow inputs to be used to develop and improve services, and a 2026 federal ruling (United States v. Heppner) confirmed AI conversation history is discoverable in litigation. For sensitive data, the safe paths are on-device AI or a verified zero-retention enterprise tier with a signed BAA or DPA. Treat the consumer ChatGPT or Gemini tab as the wrong tool the moment regulated data enters the prompt.
What is the difference between generative AI and agentic AI for sensitive work?
Generative AI produces text, images, or code from a single prompt. Agentic AI runs multi-step plans on its own, often touching tools, databases, and external systems with permission to act. For sensitive work the difference matters: a generative AI session leaks one paste at a time, while an agentic AI loop can quietly route hundreds of records through sub-processors. Agentic AI demands stricter governance, on-device execution where possible, and a redaction layer at every external boundary.
How do GDPR, HIPAA, and the EU AI Act apply to using AI tools?
GDPR treats prompt content as personal data the moment a name, email, or identifier appears, so consumer training-on-input is incompatible. HIPAA requires a Business Associate Agreement before any vendor sees protected health information. The EU AI Act phases in obligations from 2 August 2026 around transparency, documentation, and high-risk systems. The practical answer is the same across the three: prefer on-device processing, sign a BAA or DPA where required, and verify zero-retention in writing before any cloud call.
Can I use AI without sharing sensitive customer data?
Yes. The reliable approach is a layered workflow: redact identifiers on the device, run sensitive drafting on a local model, and only send sanitized prompts to the cloud for non-sensitive polish. Tools like Elephas automate the redaction step so the cloud sees a structurally complete prompt with no personally identifiable information attached. The benefits of AI carry through; the customer data stays put.
What are the best practices for protecting sensitive data when using AI tools?
Five habits cover most of the ground: keep on-device AI as the default for regulated work; require a signed BAA or DPA before any cloud call touches client data; use redaction or pseudonymization to strip identifiers at the boundary; review vendor privacy policies once a quarter, since terms change quietly; and train employees to recognize when a paste crosses the duty line. Treat data privacy regulations as the floor, not the ceiling, and build for the strictest jurisdiction your data touches.
Sources
Ready to use AI on sensitive data without exposing it?
Elephas runs locally on Mac with built-in local LLM models and Smart Redaction (beta) for the cloud calls you can't avoid.
Try Elephas for Free