Sakana Fugu: One Model to Command Them All
The Tokyo-based AI lab Sakana AI released a system called Sakana Fugu on June 22, 2026. From the outside it behaves like a single AI model. You send it one request through one connection, the same way you would message ChatGPT or Claude.
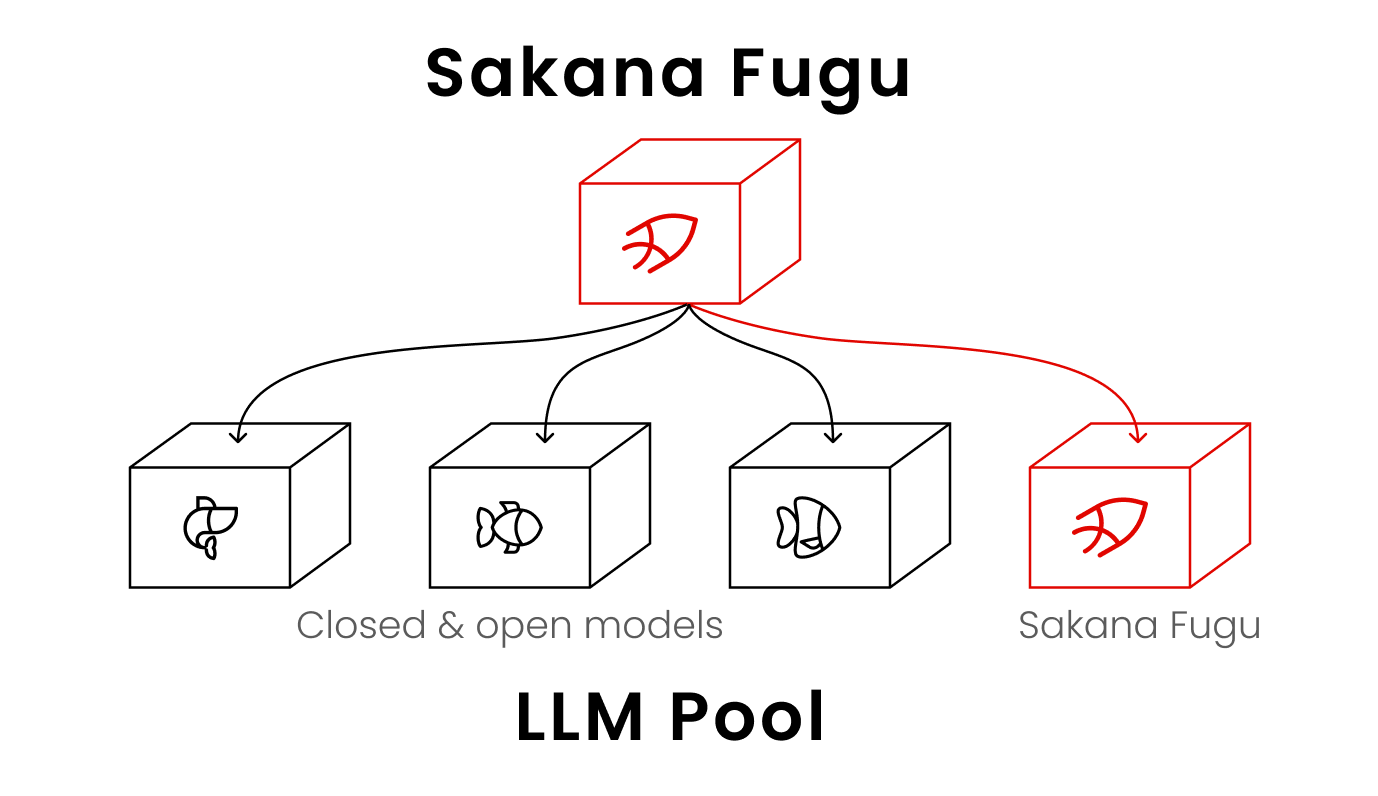
Behind that connection, Fugu hires a team of other AI models, splits the work among them, checks their answers, and returns one combined result. That design is the reason for the launch title, "One Model to Command Them All."
Sakana is betting that a coordinated team of models beats any single model working alone, and that the coordination should be invisible to the person asking the question.
This article covers the full picture: what Fugu is, why Sakana calls orchestration the next frontier, how it works, the benchmark numbers, the research underneath it, the geopolitical pitch, how to get it, where it is headed next, and the trade-off it introduces.
- Sakana Fugu is one AI model that calls other AI models for you, then merges their work into a single answer.
- It runs behind one OpenAI-compatible connection, so you do not pick models or write any routing code.
- Two versions launched: Fugu for everyday speed and cost, and Fugu Ultra for hard, multi-step problems.
- Sakana's own benchmarks place both Fugu and Fugu Ultra level with top frontier models on coding, science, reasoning, and agentic tests.
- It is generally available now, after a closed beta of about 500 users, sold by subscription and pay-as-you-go.
- Sakana says Fugu gets better over time on its own, because it can add new and stronger models to its pool.
What Sakana Fugu is
Most AI models are one large network. You ask a question and the single model answers from what it learned during training. Fugu works differently. It is a language model that was trained to call other models instead of answering everything by itself.
Sakana calls the group of callable models the "agent pool." The pool holds both closed models (the kind you reach only through a company's API) and open models (the kind anyone can download and run). When your request arrives, Fugu reads it and decides which members of the pool should handle the work.
- The pool mixes models from several different makers, not just one company.
- Fugu can also call itself, sending a smaller slice of a problem to a fresh copy of Fugu.
- Everything sits behind one connection that speaks the OpenAI API format, so existing apps can switch to Fugu with little code change.
- The person asking never sees the team. One request goes in, one answer comes out.
Why orchestration instead of bigger models
For the past few years, the main way to make AI better was to make it bigger. Companies built larger single models trained on ever more data. Sakana argues that this brute-force approach is hitting limits, because hard real-world tasks need many different skills, not one giant generalist.
Its answer is what the company calls collective intelligence: pick the right model for each part of a job, hand out the work, and combine the strengths of several models while routing around the weak spots of any single one.
Sakana says it has held this view since it was founded: the most powerful AI systems will not be isolated monoliths, but collaborative ecosystems. In the company's words, evolution innovates under constraints, and the future belongs to systems that learn to coordinate collective intelligence.
- Bigger single models cost more to train and still have blind spots.
- A team can cover skills that no single model holds on its own.
- The orchestration layer is what decides which model does what, and when.
- This reframes progress around coordination rather than raw size.
How it works under the hood
The clearest comparison is a senior project lead. You hand the lead one brief. The lead chooses which specialists to bring in, gives each a defined task, reviews the returned work, and writes the final summary. You only ever speak to the lead.
Fugu plays that role, except the specialists are AI models and the entire handoff happens in seconds.
Behind the single connection, Fugu runs four jobs on its own. For an easy question it usually skips the team and answers directly, because building a team would be slow and costly. For a hard question it assembles one on the spot, and the size and shape of that team change with the task.
- Selection: Fugu reads the request and picks the models most likely to be good at it.
- Delegation: it breaks the job into parts and assigns each part to a chosen model.
- Verification: it checks the returned work and can send a piece back out if the answer looks weak.
- Synthesis: it merges the pieces into one coherent reply.
This adaptive, per-request team is the thing a fixed single model cannot do. A standard model always uses the same network for every question. Fugu changes its approach based on what you asked, which is how it can match different specialists to different problems.
Fugu and Fugu Ultra: two models for two needs
Sakana launched two versions. Fugu is the balanced one, tuned for speed and lower cost, and meant as the default for chatbots and coding assistants. It also lets teams remove specific models from the pool to meet data or compliance rules.
Fugu Ultra aims for maximum quality on long, multi-step problems. It draws on a deeper pool and is built for heavier work such as automated research, reproducing scientific papers, cybersecurity testing, and literature or patent investigations.
- Fugu targets everyday volume, where fast and cheap matters most.
- Fugu Ultra targets hard jobs, where getting the right answer matters more than speed.
- Both are reached through the same single API.
- Both can call the full agent pool, but Ultra leans on it more aggressively.
The benchmark results
Sakana also published benchmark numbers. The table below sets Fugu and Fugu Ultra against three well-known frontier models across roughly a dozen public tests. They span coding, science, reasoning, and agentic work, meaning tasks where a model has to use tools and act over many steps.
These are Sakana's figures, and the rival scores are the ones each provider reported, so read the table as the maker's comparison rather than an independent referee's.
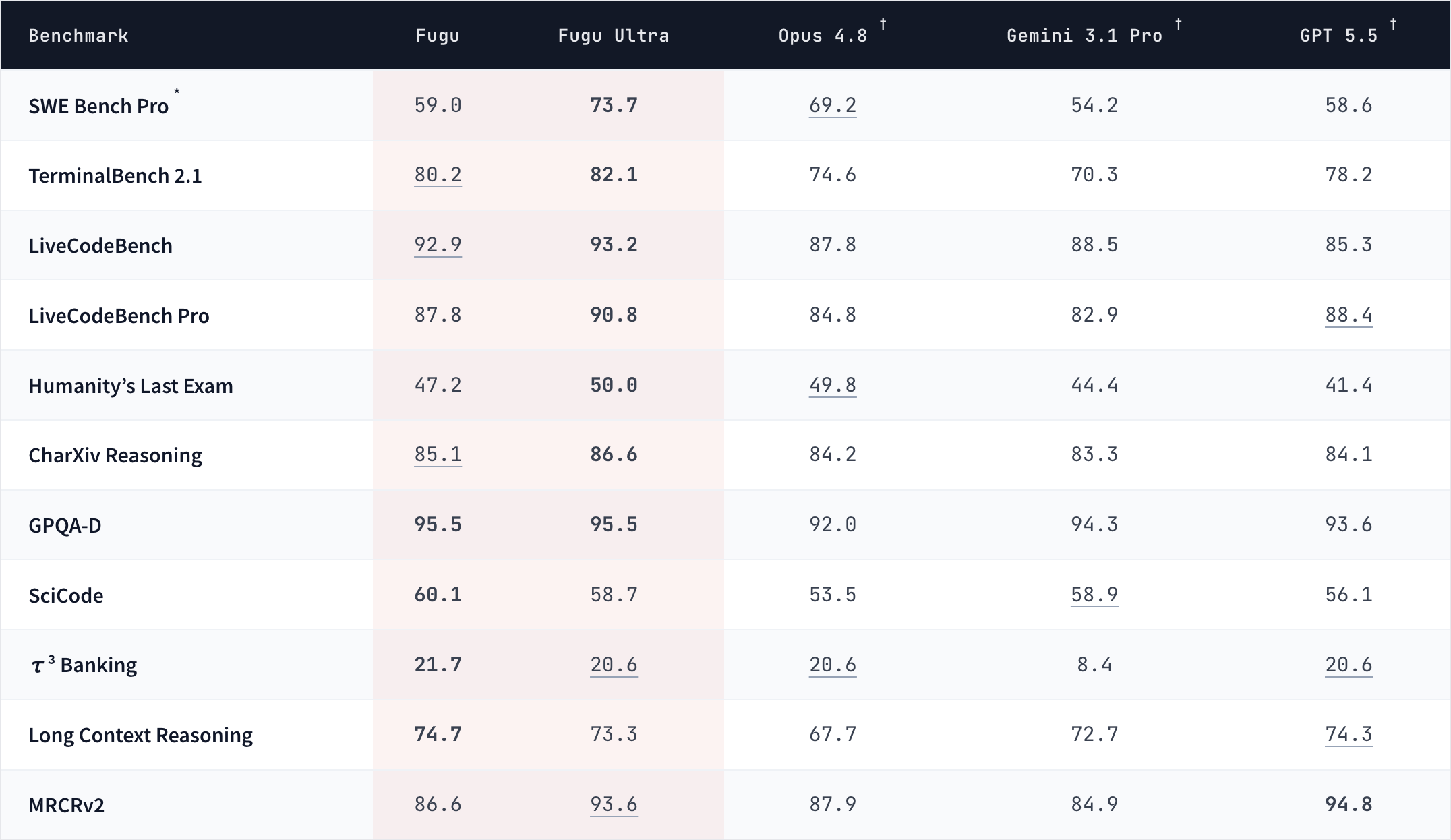
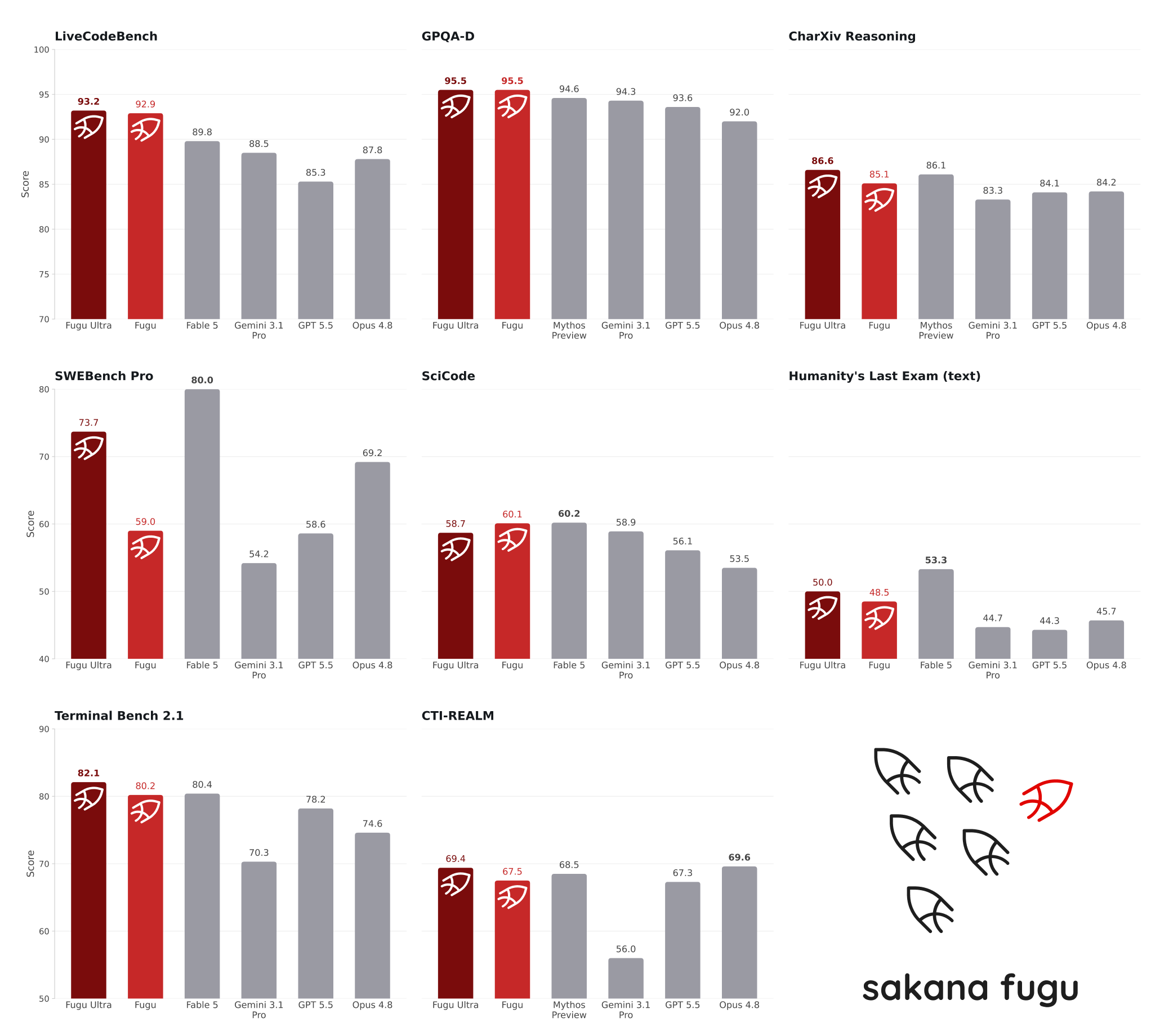
The Fugu models land at or above the frontier names on many of these tests. Fugu Ultra scores 73.7 on SWE Bench Pro, a hard software-fixing test, against 69.2 for the next closest. Both Fugu versions reach 95.5 on GPQA-D, a tough graduate-level science exam.
The cheaper base Fugu is itself frontier-class, not just a warm-up act. It tops the SciCode science-coding test at 60.1, beating Fugu Ultra and every rival, and also leads a banking tool-use test and a long-context reasoning test.
Other tests in the table include TerminalBench, LiveCodeBench, CharXiv reasoning, and CTI-REALM, an agentic cybersecurity benchmark. Where Fugu does not finish first, the gap is usually a point or two.
- Sakana also compared Fugu against two models it could not include in the pool: Anthropic's Fable 5 and Mythos Preview.
- Those two are not publicly available, so Fugu cannot call them, yet Sakana says Fugu Ultra stands level with them across engineering, science, and reasoning.
- Where both of those models had a score, Sakana used the higher of the two as the comparison point.
- The rival numbers come from each provider's own reports, and the SWE Bench Pro runs used a standard open test framework called mini-swe-agent.
What it built in testing
Benchmarks are exams. Sakana also ran practical builds where, in its own experiments, Fugu beat strong single models set to their highest effort settings: Gemini 3.1 Pro (high), Opus 4.8 (max), and GPT 5.5 (xhigh). The tasks were varied on purpose, to show range rather than a single specialty.
- AutoResearch: running a research process on its own, exploring options and learning from failed attempts.
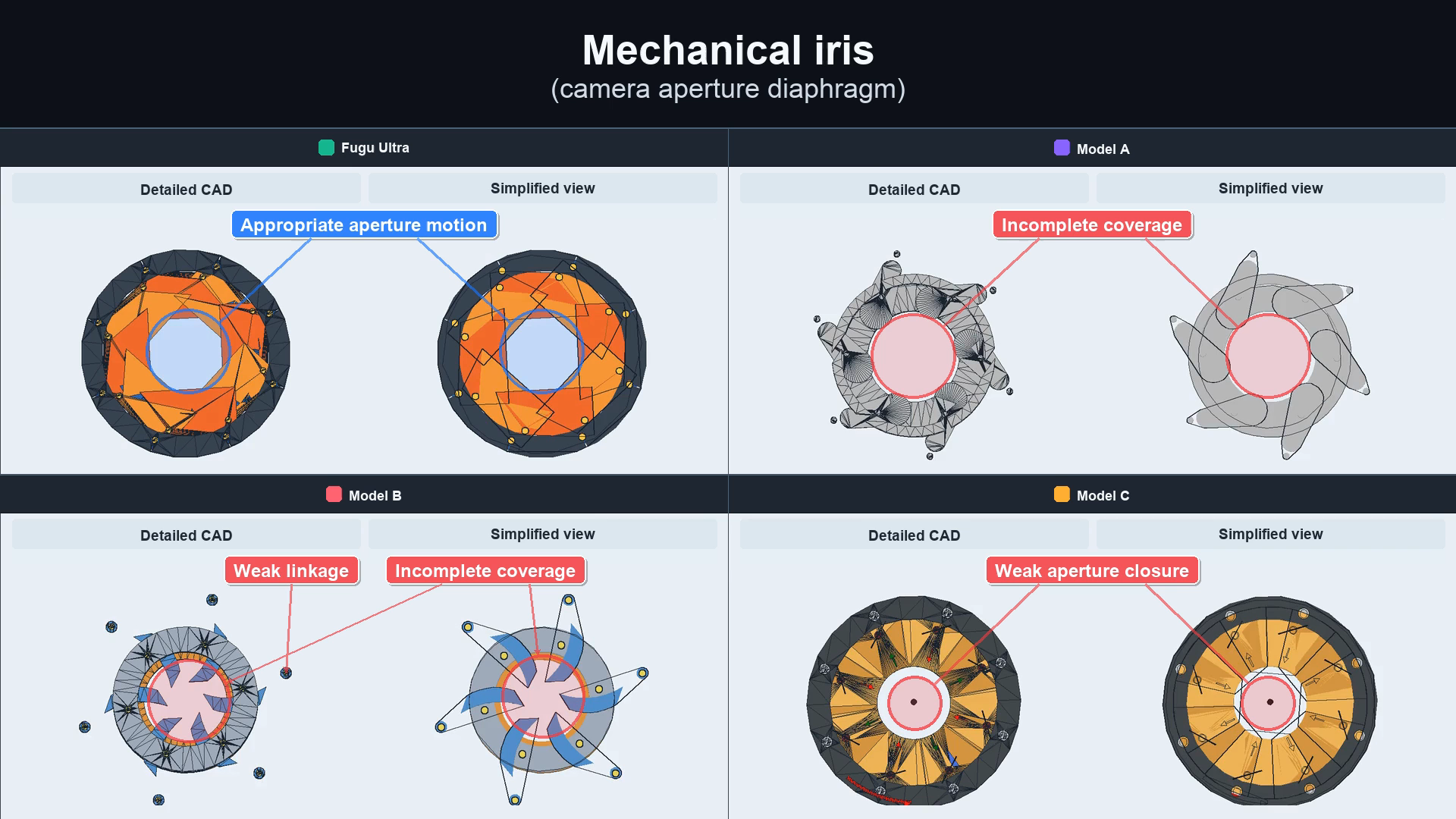
- Mechanical Design: designing a working camera iris, the ring of blades that opens and closes a camera lens.
- One-Shot Chess and a Rubik's Cube solve, both step-heavy reasoning tasks.
- Japanese Handwriting Analysis and Financial Time-Series Prediction, covering vision and forecasting.
In the mechanical design test, the difference is easy to see. Fugu Ultra produced an iris where the blades actually move and close correctly, while three single models left gaps, weak linkages, or blades that did not close. The image below shows the four attempts side by side.
What early users reported
Sakana ran a closed beta of roughly 500 users before launch and included several of their accounts in the release. The reports focus on depth and stamina on long jobs rather than raw speed.
The clearest single signal, Sakana says, came from automated data-science research. Some early users ran Fugu in a nearly hands-off research mode, where it explored ideas, ran experiments, read the results, and revised its own approach with little human help.
- A software engineer who does code review said Fugu Ultra beats GPT 5.5: where other tools flag about three issues, Fugu surfaced more than twenty, so it now runs all their reviews.
- An executive at an enterprise platform company praised "persona stability," saying Fugu held its identity across long sessions where other models drift, which for agent products can matter more than raw benchmark scores.
- A cybersecurity engineer said one scoped instruction drove a full security assessment end to end: reconnaissance, checks for cross-site scripting and SQL injection, an access-control review, and a clean report with evidence and retest steps.
- The same engineer noted Fugu stayed within scope and avoided destructive actions, and Sakana saw similar results in paper reproduction and patent investigations.
The research behind it
Fugu is not a product stitched together overnight. It grew out of two papers Sakana published at ICLR 2026, one of the main academic conferences for AI, plus a separate technical report on the full Fugu system. Both papers attack the same problem: how to make one model run a team of other models well.
The first paper, Trinity, describes an "evolved coordinator." The team used an automatic search, loosely modeled on natural selection, to discover good ways for one model to combine the strengths of several others. Better coordination strategies survived and improved over many rounds.
In that paper, the approach set a new top score at the time on LiveCodeBench, a coding test, beating the strongest single models then available.

- The second paper, the Conductor, trains a small model whose only job is to design the workflow for a team of stronger models.
- It learns three things: which agents to use, what task each one gets, and the communication setup between them, meaning which agent passes work to which.
- It is trained with reinforcement learning, meaning the model is rewarded when the final answer is good and adjusts until it reliably produces good plans.
- Together the two papers form the method that Fugu turns into a shipping product.

The bigger pitch: AI sovereignty
The technical story is only half the launch. The other half is about who controls access to strong AI. Sakana argues that leaning on a single provider for critical infrastructure, finance, or governance is now a material vulnerability for a company or a nation, and calls this a reality rather than a hypothetical.
The company points to export controls placed on Anthropic's Fable and Mythos models as its example. When a government restricts who can use a model, access can shrink or disappear for whole regions with little warning. A company that built everything on one restricted model would be left stranded.
- Sakana pitches Fugu as a hedge against that kind of shock.
- If one model in the pool becomes unavailable, Fugu can route the work to others and keep running.
- The company frames this as "AI sovereignty," the idea that an organization or country should not depend on a single foreign vendor.
- These are Sakana's claims and framing, so treat the politics as the company's argument rather than settled fact.
How to get it
Fugu moved from closed beta to general availability on launch day. Sakana is selling it in two ways, aimed at different buyers.
- A subscription, for steady individual and team use.
- Pay-as-you-go pricing, aimed at enterprise customers with variable demand.
- Both versions, Fugu and Fugu Ultra, are reached through the same OpenAI-compatible API.
- Because it copies the OpenAI format, teams can point existing tools at Fugu without rebuilding their software.
- Sakana points new users to its product page and developer console to get started.
What Sakana says comes next
Sakana calls this launch a starting point, not a finish line. Because Fugu is built on learned orchestration rather than fixed, hand-written workflows, the company says it improves on its own as the wider model ecosystem improves.
The reason is the swappable pool. When a newer and stronger model appears, Sakana can add it to Fugu's pool, and any task that model is good at gets better without the user changing a thing.
- Sakana plans to expand the pool with more expert agents, including open models and its own.
- It aims to strengthen how the agents coordinate on long-running, multi-step jobs.
- It says it will give users more control over how Fugu works on their behalf.
- Because the pool is swappable, gains from future models are meant to reach users automatically.
Sakana closed the announcement by saying it is hiring people to help build the next stage of the system.
The open question: where the data goes
One detail in the design deserves attention from anyone handling sensitive information. To route your request to the best models, Fugu has to send your request, your actual words, out to those models. A single prompt can be passed to several outside providers, and the exact mix can change from one request to the next.
For a public or low-stakes question that is fine. For confidential work, such as legal drafts, medical notes, or financial records, it is a real consideration, because the data travels to vendors the user did not individually choose.
Sakana appears aware of this. The standard Fugu version lets teams remove specific models from the pool for data and compliance reasons. That is a useful control, but also a sign that by default a request can touch many outside models.
- Orchestration spreads a request across more vendors, not fewer.
- The opt-out is a setting teams have to manage and trust, on a pool that can change.
- For regulated fields, knowing exactly which systems saw the data can matter as much as the answer's quality.
- This is a property of the orchestration approach in general, not a flaw unique to Sakana.
Bottom line
Sakana Fugu is a real step in AI design, and the idea behind it is likely to spread. Letting one capable model run a team of other models can lift the quality of hard, multi-step work, and two published research papers give the approach a serious foundation.
The benchmark numbers, while self-reported, place it among the strongest systems available.
The launch raises a question the field will keep wrestling with: as more products route your request across a pool of models, the quality can go up while your visibility into where the data went goes down.
For now, Fugu is generally available, and the rest of the industry is watching whether "one model to command them all" becomes the standard way frontier AI is delivered.
Frequently asked questions
Sakana Fugu is an AI model from the Tokyo lab Sakana AI that calls a pool of other AI models behind a single API. It splits a request among them, checks their work, and returns one combined answer.
Fugu is the faster, lower-cost default for everyday work. Fugu Ultra targets maximum quality on hard, multi-step problems and draws on a deeper pool of models.
On Sakana's own benchmarks, Fugu and Fugu Ultra match or beat Opus 4.8, Gemini 3.1 Pro, and GPT 5.5 on several coding, science, reasoning, and agentic tests. The scores are self-reported by Sakana.
Sources
- Sakana AI, Sakana Fugu release, June 22, 2026.
- Sakana Fugu Technical Report, Fugu Team, Sakana AI, 2026.
- Xu, Sun, Schwendeman, Nielsen, Cetin, Tang. Trinity: An Evolved LLM Coordinator. ICLR 2026.
- Nielsen, Cetin, Schwendeman, Sun, Xu, Tang. Learning to Orchestrate Agents in Natural Language with the Conductor. ICLR 2026.
